


📢 Quick Takes (TL;DR)
AI can now read minds in videos - New Theory-of-Mind video models can watch a scene and accurately predict people's beliefs, intentions, and emotional states, not just their actions. This leap from "what" to "why" enables AI to understand social dynamics with near-human sophistication.
Small model edge builds - Moondream 3 runs on 2B active parameters but matches frontier models. RecA needs just 27 GPU-hours to transform performance.
Open source catches the crown - Alibaba's DeepResearch matches OpenAI. Multiple teams released production-ready video and document tools. No more waiting for big tech to share their toys.
🧠 Research Highlights
Through the Theory of Mind's Eye: Reading Minds with Multimodal Video Large Language Models
Researchers built the first system that combines video and LLMs to understand what people are thinking and feeling in real-time. The pipeline answers questions about beliefs and intentions in videos, not just actions.

Why It Matters: This enables VLMs to understand the "why" behind human behavior in video, crucial for content recommendation, social media analysis, and any application requiring genuine understanding of human dynamics.
Links: Paper
RecA: Reconstruction Alignment Improves Unified Multimodal Models
UC Berkeley created RecA, a post-training method that uses visual embeddings as dense prompts to fix multimodal models. It takes just 27 GPU-hours to boost image generation from 0.73 to 0.90 on GenEval and works across all model types.
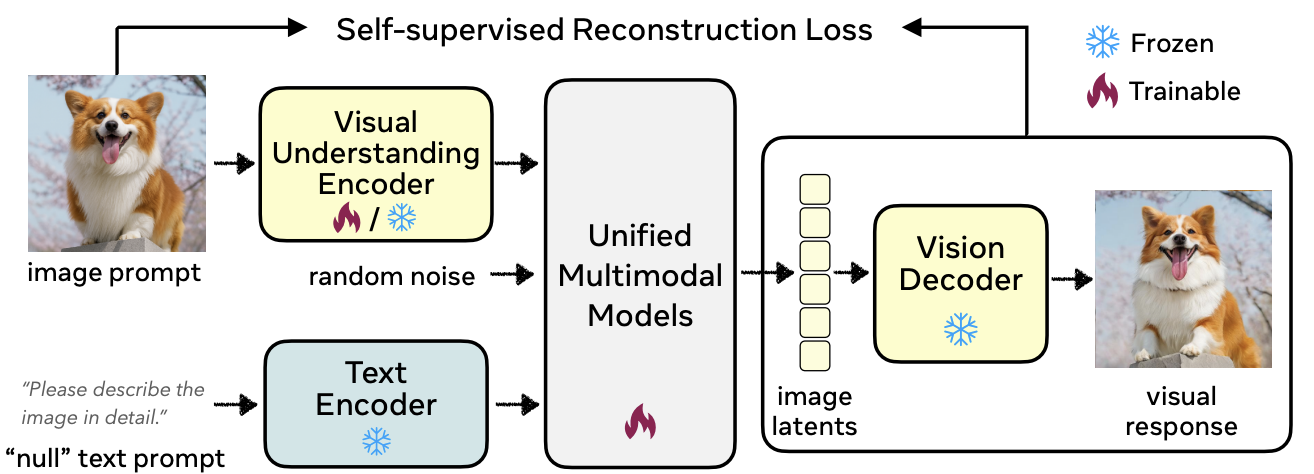
Why It Matters: You get better visual understanding without expensive captions or massive compute.
Links: Project Page | GitHub | Demo | Paper
OmniSegmentor: A Flexible Multi-Modal Learning Framework for Semantic Segmentation
NeurIPS 2025 accepted framework that unifies segmentation across five visual modalities through ImageNeXt dataset. Sets new records on NYU Depthv2, EventScape, MFNet, and other benchmarks.

Why It Matters: One model handles RGB, depth, thermal, and event cameras instead of needing separate models for each.
Links: Paper
Alibaba Tongyi DeepResearch - Open Source Deep Research Agent
Alibaba released the first open-source Web Agent matching OpenAI's Deep Research with just 30B parameters (3B active). Scores 32.9 on HLE and 75 on xbench-DeepSearch, beating all existing agents.
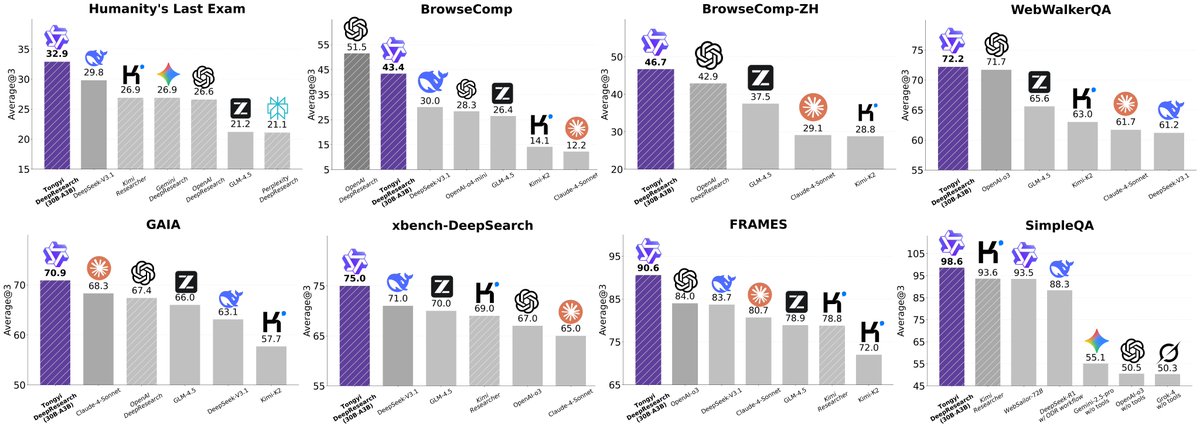
Why It Matters: You get OpenAI-level deep research capabilities for free, right now.
Links: Announcement | Blog | GitHub | Papers
LLM-I: LLMs are Naturally Interleaved Multimodal Creators
Researchers treat multimodal generation as a tool-use problem where LLMs orchestrate specialized visual tools. The system beats unified models by coordinating search, generation, and editing dynamically.

Why It Matters: Tool orchestration beats monolithic models, enabling flexible multimodal workflows that can add new capabilities without retraining the entire system.
Links: Paper
Unleashing the Potential of Multimodal LLMs for Zero-Shot Spatio-Temporal Video Grounding
Zero-shot video grounding using decomposed highlighting and temporal assembling strategies. MLLMs localize actions from text alone, beating prior methods on standard benchmarks.

Why It Matters: Video search works without training data, enabling immediate deployment for new domains and languages.
Links: Paper
Large Language Models in Document Intelligence: A Comprehensive Survey
Comprehensive survey covering recent advances in applying LLMs to document tasks. Examines multimodal understanding across document types and real-world applications.
Why It Matters: Essential reference for understanding the state-of-the-art in document AI and identifying gaps for future research.
Links: Paper
Eye, Robot: Learning to Look to Act
Framework teaching robots to coordinate visual attention with action. Robots learn where to look for effective manipulation in complex tasks.
Why It Matters: Robots that know where to look perform better, bringing us closer to human-like visual-motor coordination.
Links: Announcement | Paper | Website
LLM-JEPA: Large Language Models Meet Joint Embedding Predictive Architectures
Yann LeCun's team introduces JEPA-style training for language models. Bridges vision's embedding objectives with NLP's generative approaches, potentially leading to more efficient and capable multimodal models.
Links: GitHub | Paper
AToken: A Unified Tokenizer for Vision
Transformer tokenizer encoding images, videos, and 3D assets into shared 4D latent space. One tokenizer for all visual modalities simplifies multimodal architectures and enables seamless cross-modal transfer.
Links: Paper
🛠️ Tools & Techniques
Moondream 3 Preview - 9B Param MoE Vision Language Model
Moondream 3 uses 9B parameters but only 2B active through MoE architecture, matching frontier models. Context jumps from 2k to 32k tokens, includes visual grounding so you see what the model focuses on.
Why It Matters: Frontier performance without the frontier compute bill.
Links: Announcement | HuggingFace | Blog
LumaLabsAI Ray3 - World's First Reasoning Video Model
Ray3 generates studio-grade HDR video while reasoning about physics and consistency. Draft Mode lets you iterate quickly before final renders.
Why It Matters: Video generation that actually understands what it's creating.
Links: Announcement
Decart AI Lucy Edit - Open Source Video Editing
Lucy Edit brings advanced video editing to ComfyUI with full open-source release. Works with HuggingFace for easy deployment.
Why It Matters: Professional video editing tools without the license fees.
Links: Announcement | GitHub | HuggingFace | Platform
IBM Granite-Docling-258M - Document Conversion
IBM's 258M parameter model handles end-to-end document conversion. Processes complex layouts and formats with HuggingFace integration.
Why It Matters: Specialized document intelligence at 258M parameters proves that focused models beat general-purpose giants for specific tasks.
Links: Announcement | HuggingFace Collection | Demo
xAI Grok 4 Fast - 2 Million Context Window
Grok 4 Fast processes 2 million tokens while maintaining fast inference. Handles entire books or document collections in one pass.
Links: Announcement | Article
Alibaba Wan 2.2 Animate 14B
14B animation model for video generation with HuggingFace integration. Creates dynamic video from static inputs or text.
Why It Matters: High-quality animation generation becomes accessible without proprietary tools or massive compute resources.
Links: Announcement | HuggingFace | Demo
Meta Hyperscape Capture
Meta's immersive 3D scene capture for Meta Horizon. Creates detailed 3D representations of real environments.
Why It Matters: Real-world spaces become 3D assets instantly.
Links: Meta Experience | Announcement
Eleven Labs Studio 3.0 - AI Audio Editor with Video Support
Studio 3.0 combines voice, music, and effects in one editor. Automatic captioning, speech correction, and multiplayer commenting built in.
Why It Matters: Audio post-production without the learning curve.
Links: Announcement | Studio
VEED Fabric 1.0
New video editing platform with AI-powered capabilities. Built for creators who need speed without sacrificing quality.
Why It Matters: AI-native video editing interfaces are replacing traditional timelines for faster content creation.
Links: Announcement
📈 Trends & Predictions
AI Finally Understands People
Theory-of-Mind in video changes everything. Your AI doesn't just see someone reaching for a cup - it knows they're thirsty. This isn't pattern matching anymore. We're talking about systems that understand intentions, emotions, and social dynamics in real-time.
Think about what this means for your applications. Content moderation that understands context. Recommendation systems that know why you liked something, not just that you did. Customer service that reads between the lines. The gap between "AI that processes video" and "AI that understands situations" just closed.
The breakthrough here isn't technical - it's conceptual. We moved from asking "what happened?" to "why did it happen?" That's the difference between a security camera and a security guard. This social intelligence becomes particularly powerful in applications like contextual advertising, where understanding the emotional and social context of content enables more relevant and effective ad placement that resonates with viewers' actual mental states rather than just surface-level content matching.
Tool Orchestration Replaces Monoliths
LLM-I shows the future: AI systems that use tools, not AI systems that try to do everything. One model directing specialized tools beats one model trying to be all tools.
Your multimodal system becomes a conductor, not a one-person band. Need to edit video? Call the video tool. Need to search? Call the search tool. Need to generate? Call the generation tool. Each tool does one thing perfectly instead of everything poorly.
This isn't just more efficient, it's more capable. You can swap tools without retraining. Add new capabilities without touching core models. Fix problems in isolation. Scale what needs scaling. The monolithic model is dead.
🧩 Community + Shoutouts
Shoutout to Meta's Hypernova team - Live demos are hard. Live demos of cutting-edge AR are harder. It wasn't a flawless demo but it was still seriously impressive.
MongoDB x Llama Index drop production pipeline code - Real streaming document processing that scales. Not just a tutorial, but actual production code you can deploy. Blog | Code
Demo of the Week - AgiBot Lingxi X2 does a front flip. Yes, a robot. Yes, a real front flip. The future is here and it's doing gymnastics.
That's a wrap on this week's multimodal developments! From AI reads minds to open source SOTA models/agents and efficiency advancements, we're witnessing massive change in how AI systems understand, reason, and create across multiple modalities.
Ready to build multimodal solutions that actually work? Let's talk.
