


Quick Hits (TL;DR)
Small models match last year’s best - Claude Haiku 4.5, PaddleOCR VL 0.9B, Qwen3-VL 4B deliver frontier performance at fraction of the size.
Better sampling can beat bigger training - Harvard proves your base model already has the intelligence.
Control is composable now - Ctrl-VI and Veo 3.1 mix text, images, trajectories, and camera paths in one shot.
Research Highlights
Reasoning with Sampling: Your Base Model is Smarter Than You Think
Harvard researchers developed power sampling, an MCMC-based method that unlocks latent reasoning in base models without any training. Their approach matches or beats RL-finetuned models on MATH500, HumanEval, and GPQA while maintaining generation diversity.
Links: Project Page | Paper | Twitter
Ctrl-VI: Controllable Video Synthesis via Variational Inference
Stanford and MIT built Ctrl-VI, a video synthesis system that handles everything from text prompts to precise 4D object trajectories and camera paths. The framework uses variational inference with step-wise KL divergence minimization to produce controllable, diverse videos with 3D consistency.
Why It Matters: You get unified control from broad descriptions to pixel-perfect manipulation in a single system.
FlashWorld: High-quality 3D Scene Generation within Seconds
Tencent, Xiamen University, and Fudan created FlashWorld, which generates high-quality 3D scenes from text or image prompts in 5-10 seconds. The model produces 3D Gaussian representations directly instead of going through multi-view intermediates, combining 2D diffusion quality with 3D geometric consistency.
Why It Matters: You can now generate production-quality 3D assets faster than you can describe them.
Links: Project Page | Paper | GitHub | Announcement
Trace Anything: Representing Any Video in 4D via Trajectory Fields
ByteDance SEED released Trace Anything, which maps every pixel in a video to a continuous 3D trajectory using B-splines in a single forward pass. The model achieves state-of-the-art performance on trajectory estimation and point-tracking while being significantly faster than iterative methods.
Why It Matters: You can search videos by motion patterns instead of just visual features.
Links: Project Page | Paper | Code | Model | Twitter
VIST3A: Text-to-3D by Stitching a Multi-View Reconstruction Network to a Video Generator
ETH Zurich and Google unified a video generator with a 3D reconstruction model through model stitching, connecting a pretrained 3D foundation model into the video VAE’s latent space via lightweight linear mapping. The system generates 3D representations directly from text without needing 3D training labels.
Why It Matters: You can plug in new 3D models as they improve without retraining everything from scratch.
Links: Project Page | Paper
Virtually Being: Customizing Camera-Controllable Video Diffusion Models with Multi-View Performance Captures
Eyeline Labs enables multi-view character consistency and 3D camera control in video diffusion using 4D Gaussian Splatting and video relighting.
Why It Matters: You get consistent characters across camera angles for virtual production workflows.
Links: Project Page | Paper
LabOS: The AI-XR Co-Scientist That Sees and Works With Humans
LabOS combines computational reasoning with physical experimentation through multimodal perception and XR-enabled human-AI collaboration.
Why It Matters: AI agents can now work alongside humans in physical lab environments.

VAGEN: Reinforcing World Model Reasoning for Multi-Turn VLM Agents
VAGEN enhances multi-turn VLM agents by integrating explicit visual state reasoning into the model’s thinking process.
Why It Matters: Agents maintain better state awareness across multiple interaction turns.
Links: Project Page | Paper | Announcement
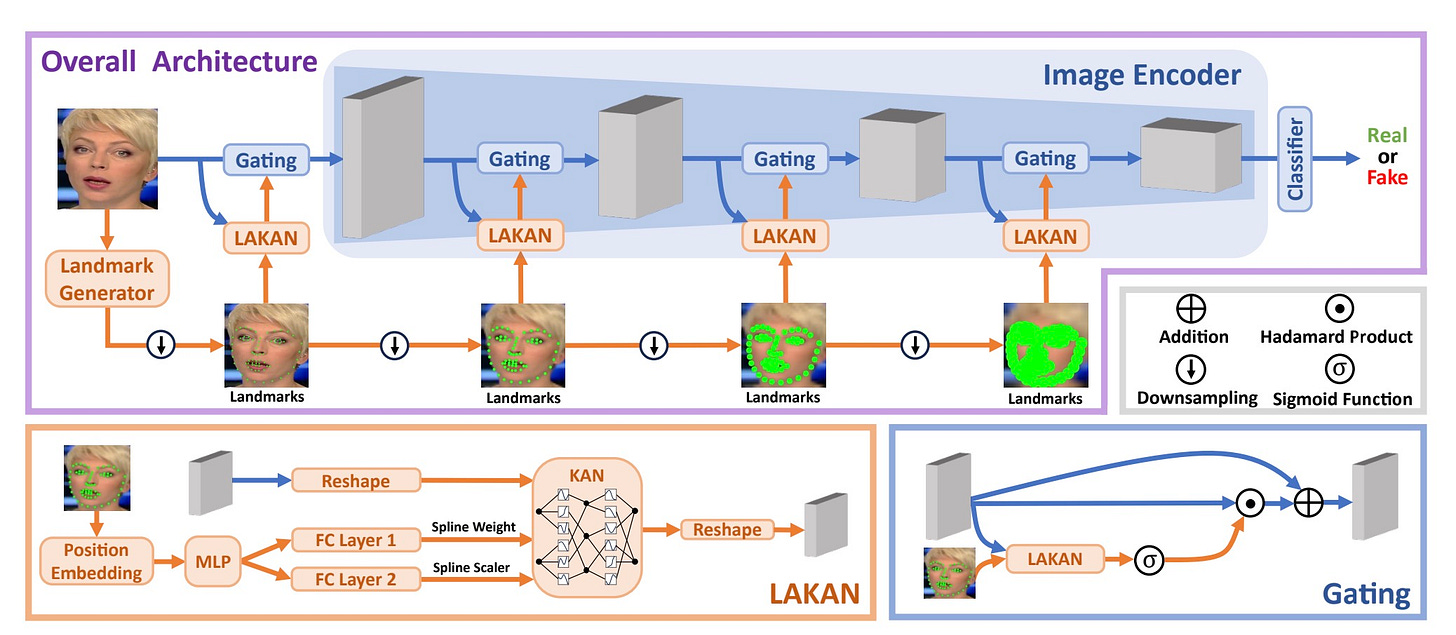
LAKAN: Landmark-Assisted Adaptive Kolmogorov-Arnold Network for Face Forgery Detection
LAKAN introduces a new network architecture for detecting face forgeries. Paper
Simple Projection Variants Improve ColBERT Performance
Mixedbread AI investigated architectural improvements to ColBERT’s projection layer for late-interaction models. Paper
Tools & Techniques
Google Veo 3.1
Google released Veo 3.1 and Veo 3.1 Fast through the Gemini API with richer native audio, better cinematic style understanding, and enhanced image-to-video. New features include ingredient-based generation with up to 3 reference images, scene extension for longer videos, and first-and-last frame interpolation.
Why It Matters: Reference image guidance and scene extension move video generation into production workflows.
Links: Announcement | Blog Post
Anthropic Claude Haiku 4.5
Anthropic released Claude Haiku 4.5, delivering near-frontier performance at one-third the cost and twice the speed of models from five months ago. The model handles real-time, low-latency tasks and is available on Claude API, Amazon Bedrock, and Google Cloud’s Vertex AI.
Why It Matters: Frontier capabilities from earlier this year now run fast and cheap enough for production use.
Links: Announcement
Baidu PaddleOCR VL 0.9B
Baidu released a 0.9B parameter multilingual VLM for OCR tasks.

Links: Hugging Face | Paper
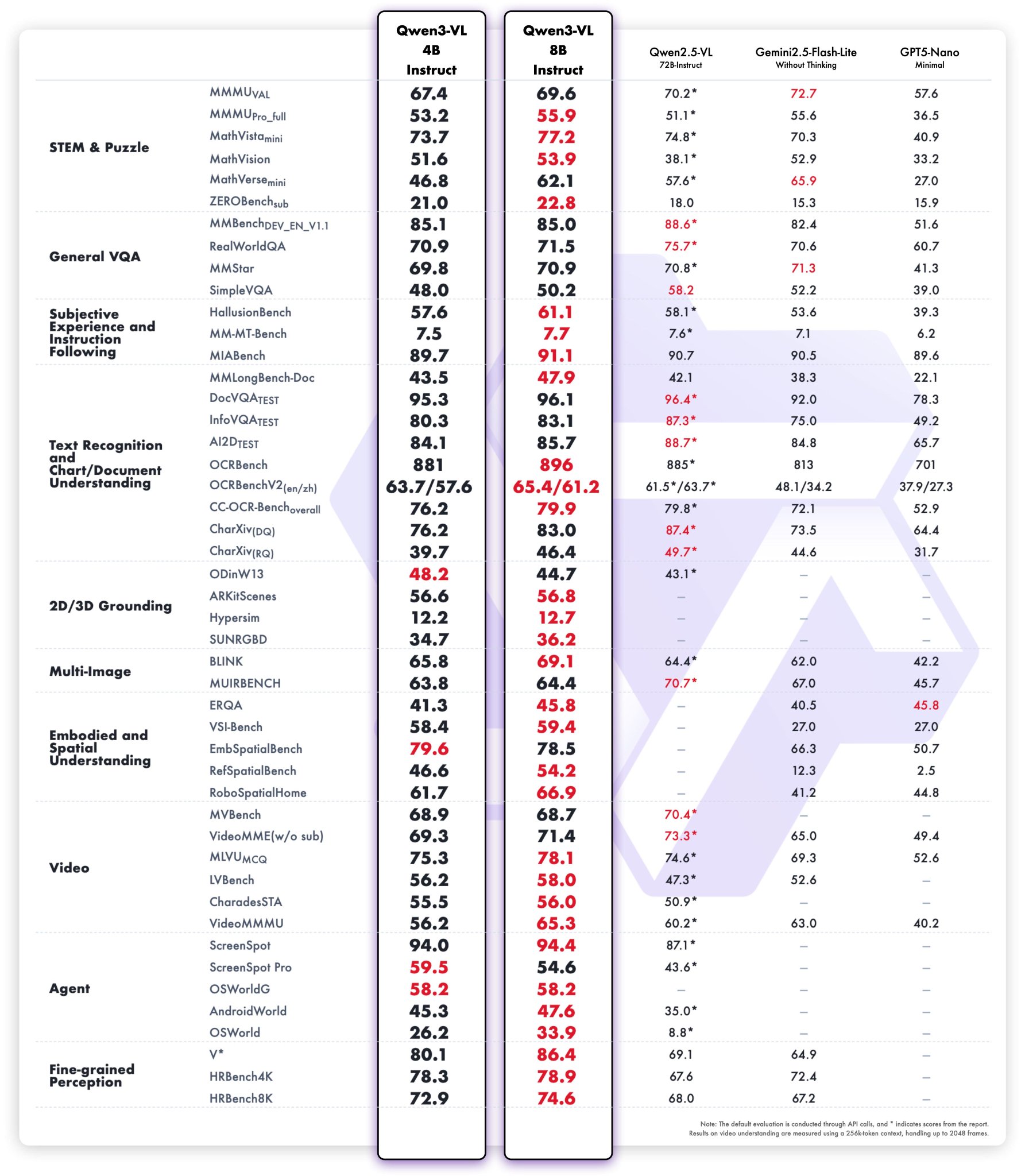
Alibaba Qwen3-VL-4B/8B
Alibaba released Qwen3-VL models in Instruct and Thinking variants. More options in the 4B-8B parameter range for vision-language tasks.
Links: Announcement | Models | Cookbooks
ImagenWorld
Google released ImagenWorld, a large-scale benchmark for image generation and editing that makes model failures more visible. Better benchmarks expose where generation models actually break.
Trends & Predictions
1. Continuous Representations Replace Discrete Ones
Trace Anything doesn’t compute frame-to-frame correspondences. It learns continuous 3D trajectories. FlashWorld doesn’t generate multiple views. It produces 3D Gaussians directly. Veo 3.1 doesn’t concatenate clips. It interpolates smooth transitions. The shift from discrete to continuous representations runs through every major paper this week.
This matters because continuous representations are more compact, more queryable, and more composable. You can sample at any resolution. You can query based on derivatives and integrals. You can blend and interpolate smoothly. Discrete representations lock you into fixed sampling rates and make interpolation messy. Continuous ones give you infinite resolution and natural interpolation. The move to continuous isn’t just cleaner math. It’s fundamentally more powerful.
2. Composable Control Wins
Ctrl-VI lets you combine text prompts with 4D trajectories and camera paths. Veo 3.1 adds reference images and scene extension. VIST3A stitches models together with linear mappings. The pattern is clear: systems that combine multiple control signals beat single-mode approaches. You don’t choose between high-level creativity and low-level precision anymore. You get both. This matters because creative workflows are messy. You need broad strokes and fine details at different stages. Composable control means you can start with a text prompt, refine with reference images, adjust specific object paths, and modify camera movement without switching tools.
Community + Shoutouts
Builder of the week: Real-time head pose estimation for perspective correction. Clean implementation, practical use case.
Links: Reddit
ComfyUI-QwenVL brings seamless multimodal AI to ComfyUI workflows with text generation and image understanding.
Links: GitHub

That’s a wrap for Multimodal Monday #29! Claude Haiku 4.5 brings high performance to low-latency edge scenarios, LabOS facilitates human-AI collaboration in physical lab settings via XR, and Ctrl-VI provides flexible control over video synthesis from prompts to trajectories, this week illustrates how refinements in efficiency, state management, and controllability are helping multimodal systems integrate more reliably into collaborative and creative processes.
Ready to build multimodal solutions that actually work? Let's talk.
